An EPPC26 Devlog — Automating Conference Recaps with Claude Code
European Power Platform Conference, Copenhagen | June–July 2026 | Category: Claude Code
Every conference blogger knows the real cost isn’t sitting in the session — it’s everything that happens after. Record, transcribe, write, find an image, publish. Do that ten times in one week and the backlog wins. So instead of writing about someone else’s session this time, here’s a recap of the thing that made writing the other recaps possible: the pipeline built during EPPC26 itself, live, between sessions.
The Manual Version
The starting point was a Plaud Note Pro recorder and a chain of manual steps: pull the recording down from Plaud’s cloud, convert OGG to MP3 in VLC, paste it into Word Online for transcription, feed the transcript to an AI for a draft, hunt down a photo in Google Photos, and finally paste everything into WordPress by hand. Every step worked. None of them scaled past two or three sessions before the backlog became the whole job.

The sharpest constraint turned out to be a quota, not a skill gap: Plaud’s built-in transcription caps out at 300 minutes a month. A single-track conference day can burn through that on its own.
What Got Automated
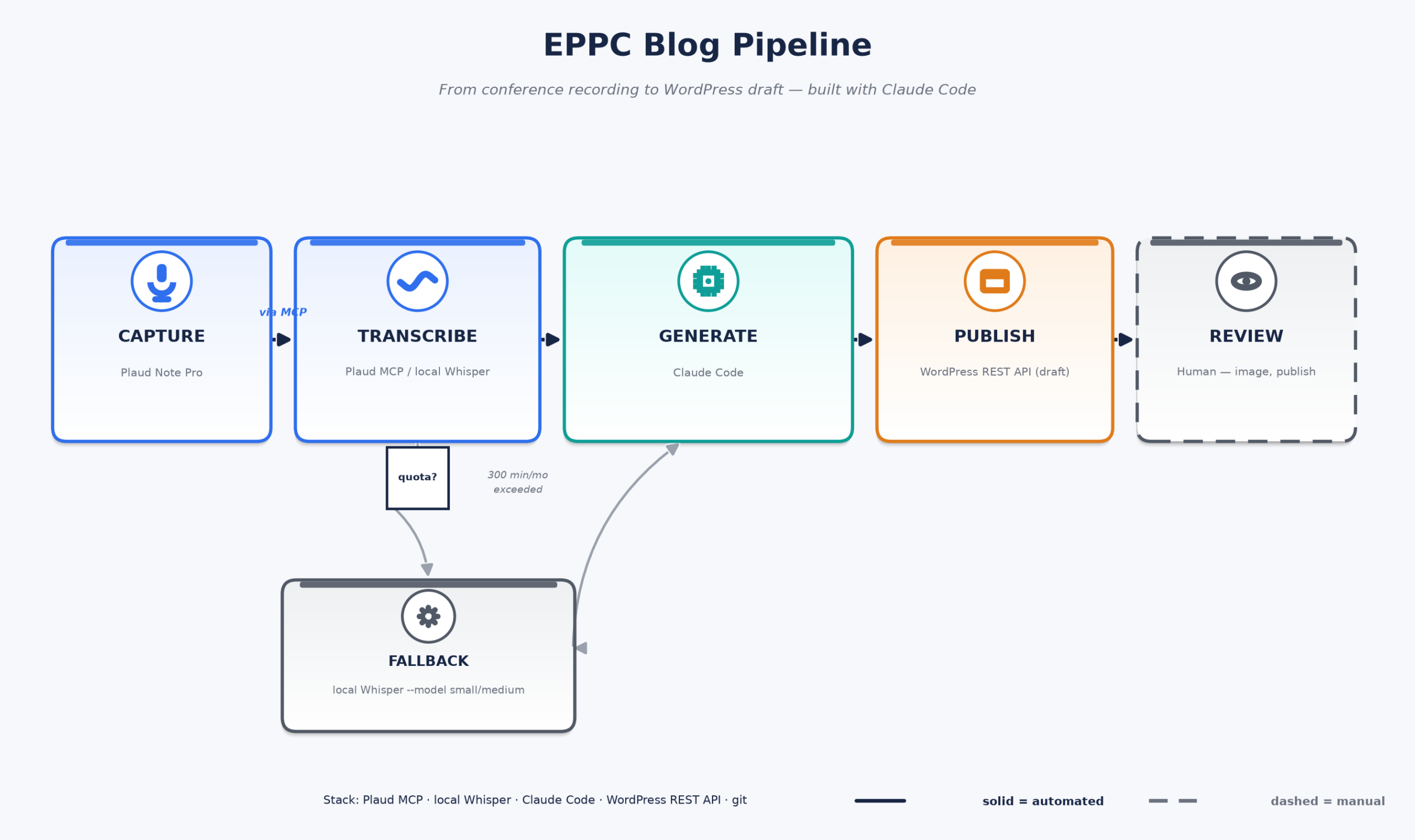
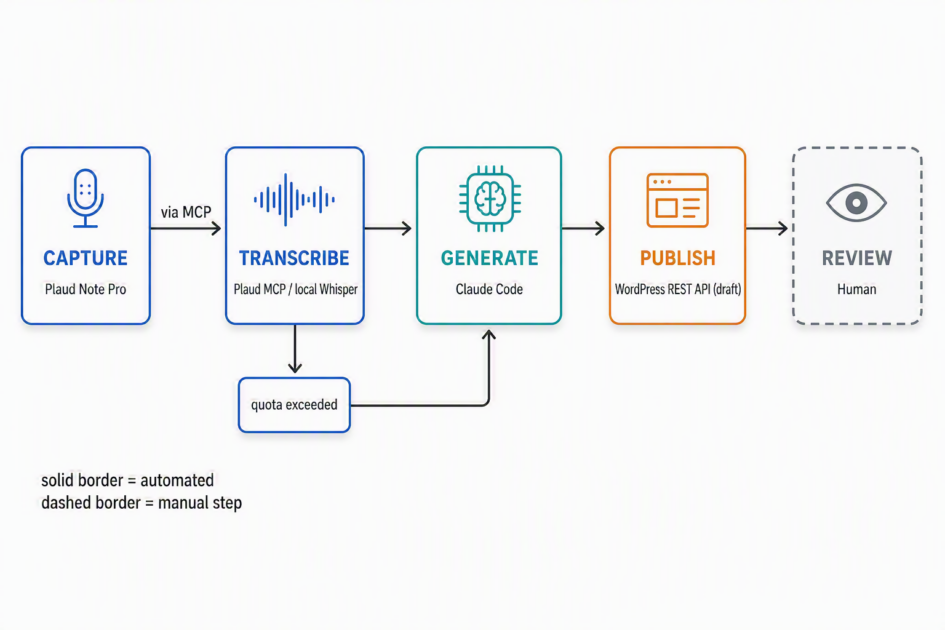
Plaud Note Pro (recording)
│
▼
Plaud Cloud ──► Plaud MCP (get_transcript) ← quota-limited, used first
│
▼ (once the quota runs out)
Manual pull from Plaud Web (MP3)
│
▼
Local Whisper transcription
│
▼
Claude → blog draft (.md)
│
▼
WordPress REST API → draft post
│
▼
Kalle: adds the image, reviews, publishes
Plaud does ship an official MCP server, and it’s genuinely good — Finnish transcripts come back with millisecond-accurate timestamps and speaker labels, and it even picked out “Karl” by name in one recording. But it’s a cloud service with a monthly ceiling, so it’s the fast path for a session or two, not the whole conference. Once the quota is gone, the fallback takes over: pull the raw audio down and run it through a local Whisper install instead. Whisper reads compressed audio directly, so the OGG-to-MP3 conversion step that used to be mandatory just disappeared — one less manual hop in the chain.
Once there’s a transcript, Claude turns it into a structured post — title, intro, key points, a takeaways section, closing thought — and drops it as a markdown file, git-tracked alongside everything else in the project. From there, a small WordPress integration takes over: a dedicated account with Contributor-level access and posts the draft via the REST API.
The Deliberate Gaps
Two things were not automated, on purpose.
Images stay manual. The pipeline could fetch or generate a header image automatically, but a hand-picked photo from the actual talk beats a generic stock image or an AI render every time, and the review step is cheap. So the script pauses and asks for a media ID rather than guessing.
Publishing stays manual. The account can create drafts but deliberately cannot publish, edit a published post, or delete anything — the WordPress role has none of those capabilities. Every post gets a human read-through before it goes live. That’s not a limitation that needs fixing; it’s the actual design.
What Went Wrong (and What Fixed It)
The server hosting this pipeline has no swap partition. Running Whisper on a batch of recordings back-to-back exhausted RAM and took the whole machine down mid-conference. The fix was mundane — free up disk space, drop from the medium model to small, and process files one at a time instead of in parallel — but it’s the kind of lesson that only shows up under real load, not in a five-minute test.
There was also a quieter platform obstacle on the WordPress side: a security plugin blocking the category and tag REST endpoints outright, even for an authenticated request. The workaround was to request published posts with _embed instead, which returns category and tag names as a side effect of the normal post payload — no direct taxonomy call needed.
Why This Belongs in the Claude Code Category
The pattern underneath all of this — local tool (Whisper) plus an LLM (Claude) plus a REST API, wired together and driven from a coding agent instead of a hand-built script — is the same shape as the agentic patterns showing up all over this year’s session list. The difference here is scale: no orchestration platform, no enterprise governance layer, just a project folder, a git repo, and a conversation with Claude Code that turned into working automation between two conference talks.
The next milestone is the one still open on the list: an hourly scheduled check for new recordings, so the pipeline notices new audio on its own instead of waiting to be told. For a one-person, one-week conference workflow, that’s the last manual step worth removing.
Built live during EPPC26, Copenhagen, June 29 – July 2, 2026.
Stack: Plaud MCP, local Whisper, Claude, WordPress REST API.